[딥러닝 스터디] 정규화를 왜 하는걸까?
정규화

- Local optimum에 빠지는 가능성을 줄이기 위해 사용함.

- 학습할 때 분산이 큰 쪽으로 먼저 학습을 해 나감.
- 학습률을 작게 해야함. (분산이 다르기 때문에 학습률이 커지면 분산이 작은 쪽은 발산을 해 버림)
- 정규화를 하면 경사하강법이 어디에서 시작되어도 일정하게 학습을 해 나감.
배치 정규화
배경
- Deep learning은 주로 SGD방법을 통하여 매개변수를 update 함.
- 학습속도를 높이려면 learning rate를 높여야 했는데, 이는 gradient vanishing or gradient exploding 문제가 발생함.
- 따라서 학습 속도를 높이면서 위의 문제가 발생하지 않는 방법이 없을까?
장점
- 학습률을 키워 학습속도를 증가시킬 수 있다.
- 가중치 초기화에 대한 고민이 필요없다.
- Dropout을 사용하지 않아도 된다. (Regularizer 역할을 해 줌.)
Covariate Shift
- Train 데이터와 test데이터의 분포가 다른 것.
- 분포가 다르다면 train으로 잘 학습해도 test데이터의 예측 값은 좋지 않을 것임.
Internal Covariate Shift (ICS)
- 딥러닝에서 입력 값의 분포가 달라지는 것을 의미.
- 곱해지는 가중치가 계속 학습되면서 바뀜.

- 층의 깊이가 깊어질수록 분포의 변동성은 커지게 되고 이로 인해 학습을 해 나가는데 어려움을 겪거나, 학습하는 데 시간이 오래걸림.
- 이를 ReLU나 가중치 초기화, 학습률을 낮추면서 해결할 수 있지만, 이것만으로 해결되지 않는 경우도 있음.
- 이러한 간접적인 방법이외 학습과정에서 안정적으로 학습하면서 속도를 가속시킬 수 있는 방법을 찾고 싶음.
- ICS를 감소시키는 방법은 whitening이 있음.
-
즉 각 층에서 입력 값을 매번 평균이 0 분산이 1로 정규화 하자는 것임.
- 매번 그렇게 정규화를 한다면 계산량이 증가함.
-
파라미터의 영향이 무시됨. (편향 b의 영향이 무시됨.)
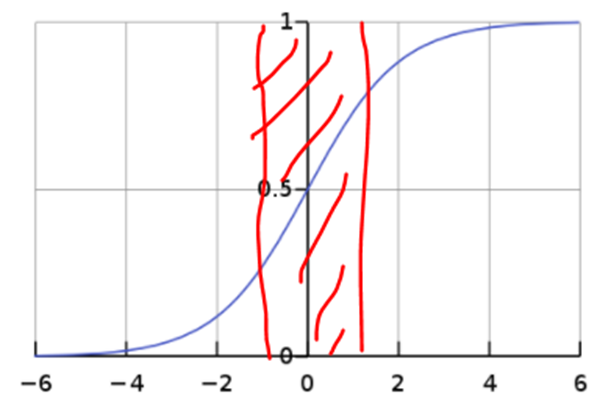
- 입력이 N(0,1)로 된다면 시그모이드 함수의 빨간색 부분에 데이터가 몰려있을 것임.
- 빨간색 부분은 선형성을 띄는 부분으로 활성화 함수를 거쳐도 비선형성을 갖지 못하고 선형성을 갖기 때문에 활성화 함수를 사용하는 의미가 없음.



- Whitening처럼 평균 0 분산이 1이 되도록 정규화를 한 입력 값에 감마와 베타라는 또 다른 매개변수가 추가됨.
- 감마는 주로 1, 베타는 주로 0에서 시작해서 학습해 감.
- 이를 통해 시그모이드 함수의 선형 구역을 벗어남.
- 정규화는 전체 dataset을 처리하지만 SGD는 batch 단위로 데이터를 처리.
- 따라서 normalize도 배치단위로 해줌.
- 이를 통해 연산량이 줄어든다는 장점이 있음.
단점
- RRN에서 사용할 수 없음. (사용하는 방법도 제시는 되어 있음.)
- 배치크기에 의존적임. (배치 사이즈가 커야한다는 단점. 주로 배치사이즈는 작게 두는 것이 좋다고 알려져 있음.)